
一、概率论基础
1、概率 p(x)
事件A的概率是对事件A在试验中出现的可能性大小的一种度量,事件A的概率表示为 $p(A)$。
2、概率分布
反映随机变量 $X$(可能是离散型、也可能是连续型)的所有可能取值(如$X=x_1,x_2,\dots$),将随机变量取这些值的概率一一列举出来的概率分布就是该随机变量的概率分布。
对于离散型随机变量,它的概率分布可以用枚举法表示$P(X=x_i)$;对于连续型随机变量,它的概率分布可以用$P(X)$表示。
3、概率密度函数
设 $X$ 为一连续型随机变量,$x$为任意实数,$X$的概率密度函数记为$f(x)$,概率密度函数满足条件:
(1)$f(x) \ge 0$;(2)$\int_{+\infty}^{-\infty}f(x)dx=1$。
概率密度函数$f(x)$和概率$p(x)$的关系:对于任何实数$x_1 < x_2$,$p(x_1 < x < x_2)$是该概率密度曲线下从$x_1$到$x_2$的面积:
$p(x_1 < x < x_2) = \int_{x_1}^{x_2} f(x) \, dx$
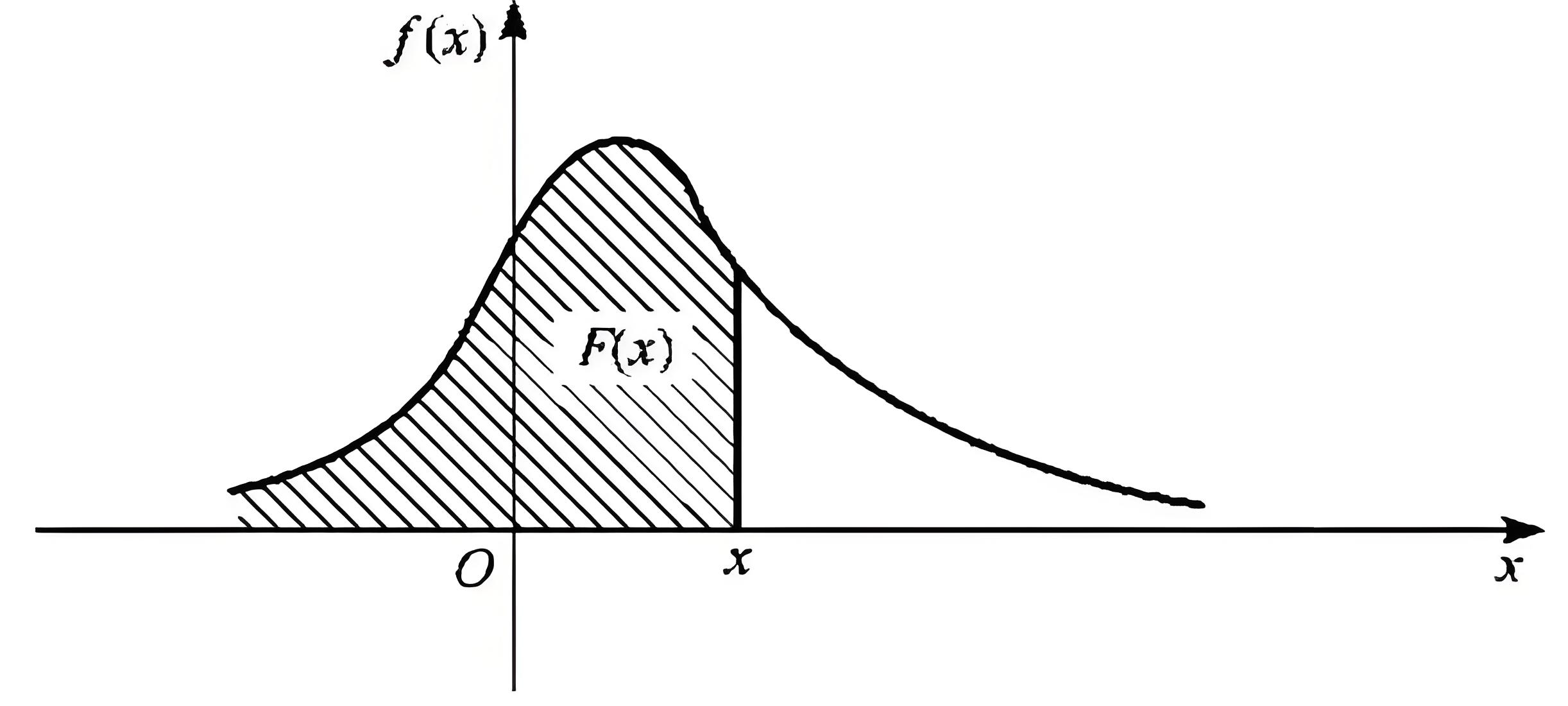
4、分布函数(累积分布函数,CDF)
连续型随机变量的概率也可以用分布函数 $F(x)$ 来表示,定义为:
$$ F(x) = p(X \le x) = \int_{-\infty}^{x} f(t) \, dt $$其中,$-\infty < x < +\infty$。
概率密度函数是分布函数的导数,而分布函数是概率密度函数从负无穷到指定点的积分。物理意义上,分布函数是概率密度函数曲线下小于 $x$ 的面积。
Probability Density Function
5、均值和方差
凡是随机变量符合一定的分布,就有均值和方差,因此确定了一个分布的均值和方差,这个分布就100%确定了。
均值(期望) $E(X)$:
- 离散:$E(X) = \sum x P(x)$
- 连续:$E(X) = \int_{-\infty}^{+\infty} x f(x) \, dx$
方差 $S^2$:
每个样本点与均值之差的平方和除以样本数量。
6、正态分布(高斯分布)
正态分布记作 $X \sim N(\mu, \sigma^2)$,概率密度函数为:
$$ f(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}} $$当 $\mu = 0$,$\sigma = 1$ 时称为标准正态分布。
7、似然函数(Likelihood Function)
似然函数 $\mathcal{L}(\theta|x)$ 是在给定观测数据 $x$ 的情况下,关于参数 $\theta$ 的函数。它描述了在不同参数取值下观察到当前数据的概率。
概率描述“已知参数时数据的分布”,似然描述“已知数据时参数的可能性”。
8、KL散度(Kullback-Leibler Divergence)
KL散度衡量两个概率分布之间的差异(信息损失)。
$KL(Q||P)$ 表示用分布 $Q$ 来近似 $P$ 时损失的信息量。注意 $KL(Q||P) \neq KL(P||Q)$(非对称)。
二、扩散模型核心公式推导
1、AutoEncoder (AE)
AE思路简单:输入数据通过Encoder压缩到低维,再通过Decoder重建回原始维度,直接计算重建误差(MSE)实现无监督特征提取。
2、Variational AutoEncoder (VAE)
VAE是AE的概率版本,不再输出确定性隐变量,而是输出一个高斯分布的参数(均值 $\mu$ 和方差 $\sigma$),从该分布中采样得到隐变量 $z$。
输入 [128, 784] → Encoder 输出 $\mu$[128,8] 和 $\sigma$[128,8] → 从该高斯分布采样 z[128,8] → Decoder 重建 [128, 784]。
VAE的核心目标是建模数据分布 $P(X)$,可表示为:
$$ P(X) = \sum P(z) P(x|z) \quad \text{(离散形式)} $$ $$ P(x) = \int_{z} P(z) P(x|z) \, dz \quad \text{(连续形式)} $$其中 $z \sim N(0,1)$,$x|z \sim N(\mu(z),\sigma(z))$。
VAE 证据下界(ELBO)推导
目标是最大化 $\log P(x)$:
$$ \begin{align} \log P(x) &= \log \int_{z} q(z|x) \frac{P(x,z)}{q(z|x)} \, dz \\ &= \int_{z} q(z|x) \log \frac{P(x,z)}{q(z|x)} \, dz + KL(q(z|x) || P(z|x)) \\ &= L_b + KL(q(z|x) || P(z|x)) \end{align} $$由于KL项 ≥ 0,因此 $L_b \le \log P(x)$,$L_b$ 即为证据下界(ELBO)。
进一步展开 $L_b$:
$$ L_b = -KL(q(z|x) || P(z)) + \mathbb{E}_{q(z|x)}[\log P(x|z)] $$第一项对应正则化损失(让后验接近先验),第二项对应重建损失。
VAE通过Encoder学习后验 $q(z|x)$,Decoder学习生成模型 $p(x|z)$,并通过ELBO实现端到端的优化,为后续扩散模型(Diffusion Models)奠定了坚实的概率建模基础。